A common question I run into is how does Apache Spark™ perform fast counts against Parquet files. TL;DR: Spark is able to read the parquet metadata without needing to read the entire file. If you want to dive into the details, please continue!
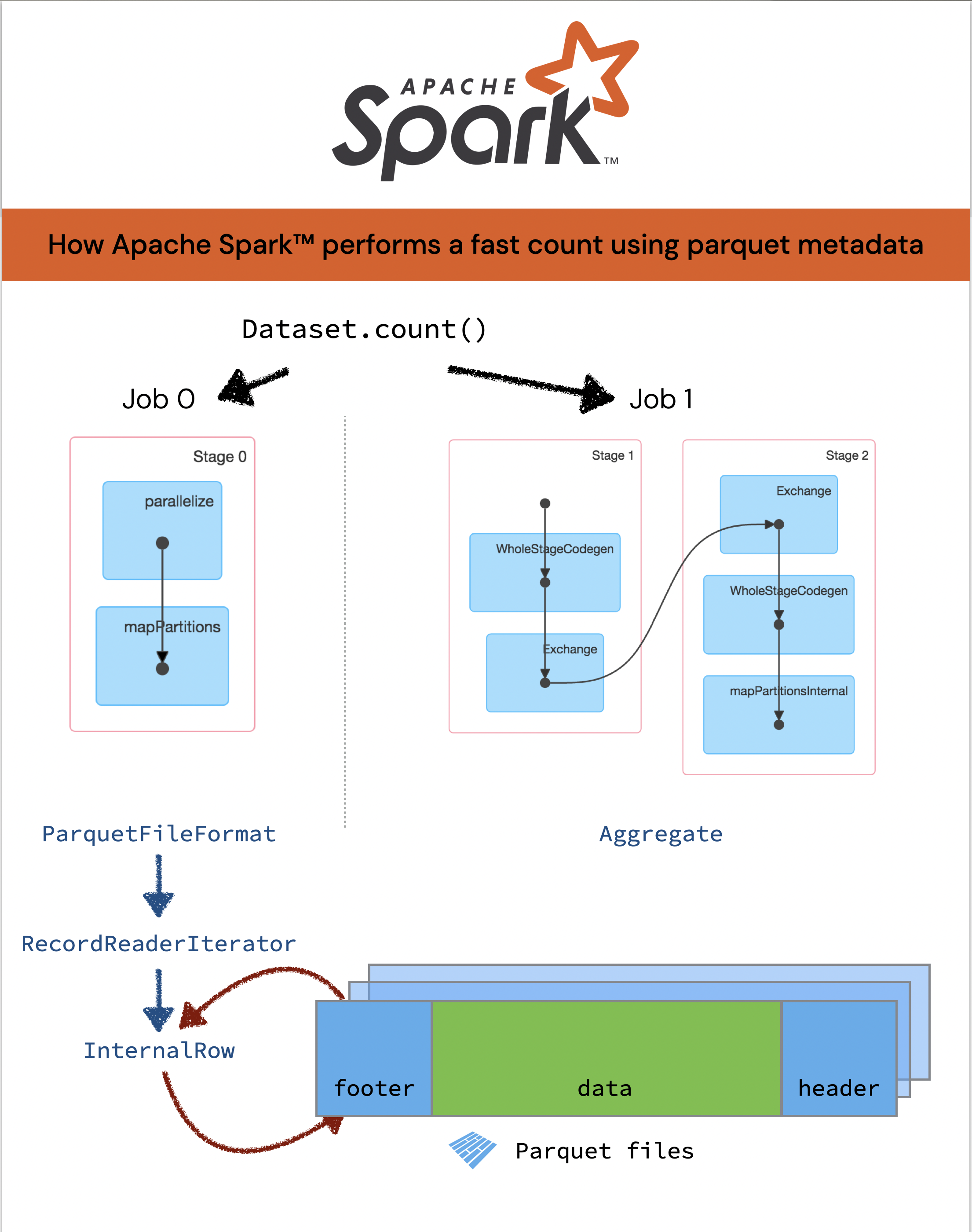
The rest of this post contains the basics surrounding how an Apache Spark row count uses the Parquet file metadata to determine the count (instead of scanning the entire file). For a query like spark.read.parquet(...).count(), the Parquet columns are not accessed, instead the requested Parquet schema that is passed down to the VectorizedParquetRecordReader is simply an empty Parquet message. Thus, Spark is calculating the count using the Parquet file footer metadata.
Note, this post is based on an earlier version (December 2016) of my Github note.
Let’s start with Jobs
When Apache Spark executes a query, it creates multiple jobs and associated stages, each with its own set of tasks. Ultimately, the query will then distribute the tasks across multiple nodes. For this query spark.read.parquet(...).count(), the jobs and stages behind the can be seen in the Spark DAG (from the Spark UI) below.

By default, Spark will generate two jobs to perform this calculation. The first job reads the file from the data source and second job performs the aggregration.


Normally its all about WholeStageCodegen
In most aggregation cases with Apache Spark, we would dive into WholeStageCodegen per Job 1. At planning time, Spark generates Java byte code for many Spark operations including aggregations. The Spark engine Catalyst Optimizer generates a logical plan, multiple physical plans, and utilizes a cost optimizer. This is similar to how relational database systems operate. The last step is to generate the byte code via Code Generation.

If you want to dive deeper into this, here are some great resources:
- Structuring Spark: DataFrames, Datasets, and Streaming by Michael Armbrust.
- Deep Dive into Spark SQL’s Catalyst Optimizer
- Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop.
Check out What’s new in Apache Spark 3.0 for a quick primer including Adaptive Query Execution (AQE).
Recall that Spark can perform a fast count using Parquet metadata instead of reading the data source or Parquet files. So instead of diving into FileScanRDD (scanning the Parquet files) to WholeStageCodeGen (Code Generation) for most queries per Job 1, let’s take a look at the code flow of Job 0.
Let’s look at the RecordReaderIterator
When reading the file(s) from the data source, the generated Java code from DataFrameReader interacts with the underlying data source ParquetFileFormat. This in term utilizes the RecordReaderIterator, which is used internally by the Spark Data Source API. The following is the breakdown of the code flow:
org.apache.spark.sql.DataFrameReader.load (DataFrameReader.scala:145)
https://github.com/apache/spark/blob/689de920056ae20fe203c2b6faf5b1462e8ea73c/sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala#L145
|- DataSource.apply(L147)
https://github.com/apache/spark/blob/689de920056ae20fe203c2b6faf5b1462e8ea73c/sql/core/src/main/scala/org/apache/spark/sql/DataFrameReader.scala#L147
|- package org.apache.spark.sql.execution.datasources
https://github.com/apache/spark/blob/689de920056ae20fe203c2b6faf5b1462e8ea73c/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/DataSource.scala
|- package org.apache.spark.sql.execution.datasources.parquet [[ParquetFileFormat.scala#L18]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L18
|- class ParquetFileFormat [[ParquetFileFormat.scala#L51]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L51
Following the flow of the code, its job (pun intended) is access the ParquetFileFormat data source when utilizing the DataFrameReader. This is all within the context of the Data Source API org.apache.spark.sql.execution.datasources.
RecordReader paths: (Non)VectorizedParquetRecordReader and InternalRow
One interaction path for the for the Java byte code is via the VectorizedParquetRecordReader (and NonVectorized) path; below is the code flow for the former.
|- package org.apache.spark.sql.execution.datasources.parquet [[ParquetFileFormat.scala#L18]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L18
|- class ParquetFileFormat [[ParquetFileFormat.scala#L51]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L51
|- val vectorizedReader = new VectorizedParquetRecordReader()
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L376
|- VectorizedParquetRecordReader.java#48
https://github.com/apache/spark/blob/39e2bad6a866d27c3ca594d15e574a1da3ee84cc/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/VectorizedParquetRecordReader.java#L48
|- SpecificParquetRecordReaderBase.java#L151
https://github.com/apache/spark/blob/v2.0.2/sql/core/src/main/java/org/apache/spark/sql/execution/datasources/parquet/SpecificParquetRecordReaderBase.java#L151
|- totalRowCount
The SpecificParquetRecordReaderBase.java (Line 13 in the above code snippet) references the Improve Parquet scan performance when using flat schemas commit as part of [SPARK-11787] Speed up parquet reader for flat schemas.
Another path for the Java byte code to interact with the underlying data source is through the RecordReaderIterator that returns an InternalRow via the code flow below.
|- package org.apache.spark.sql.execution.datasources.parquet [[ParquetFileFormat.scala#L18]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L18
|- class ParquetFileFormat [[ParquetFileFormat.scala#L51]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L51
|- val iter = new RecordReaderIterator(parquetReader) [[ParquetFileFormat.scala#L399]]
https://github.com/apache/spark/blob/2f7461f31331cfc37f6cfa3586b7bbefb3af5547/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/parquet/ParquetFileFormat.scala#L399
|- class RecordReaderIterator[T] [[RecordReaderIterator.scala#L32]]
https://github.com/apache/spark/blob/b03b4adf6d8f4c6d92575c0947540cb474bf7de1/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/RecordReaderIterator.scala#L32
|- import org.apache.hadoop.mapreduce.RecordReader [[RecordReaderIterator.scala#L22]]
https://github.com/apache/spark/blob/b03b4adf6d8f4c6d92575c0947540cb474bf7de1/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/RecordReaderIterator.scala#L22
|- import org.apache.spark.sql.catalyst.InternalRow [[RecordReaderIterator.scala#L24]]
https://github.com/apache/spark/blob/b03b4adf6d8f4c6d92575c0947540cb474bf7de1/sql/core/src/main/scala/org/apache/spark/sql/execution/datasources/RecordReaderIterator.scala#L24
What is Internal Row?
The logic surrounding InternalRow via RecordReaderIterator is
- Not needing to reading any Parquet columns to calculate the count
- The passing of the Parquet schema to the
VectorizedParquetRecordReaderis actually an empty Parquet message - Computing the count using the metadata stored in the Parquet file footers.
To work with the Parquet file format, internally, Apache Spark wraps the logic with an iterator that returns an InternalRow; more information can be found in InternalRow.scala. Ultimately, the count() aggregate function interacts with the underlying Parquet data source using this iterator. This is true for both vectorized and non-vectorized Parquet reader.
Bridging Apache Spark count with Parquet metadata
So how do we bridge the Apache Spark count (i.e., spark.read.parquet(...).count(), or more eloquently Dataset.count()) with the Parquet metadata count calculated in the aggregation. After all these two steps are performed in two separate jobs (job 0 and job 1).

To bridge these two jobs (i.e., the Dataset.count() with the Parquet metadata count via InternalRow)
- The
Dataset.count()call is planned into an aggregate operator with a singlecount()aggregate function. - Java code is generated (i.e.
WholeStageCodeGen) at planning time for the aggregate operator as well as thecount()aggregate function. - The Java byte code interacts with the underlying data source ParquetFileFormat with an RecordReaderIterator, which is used internally by the Spark data source API.
Discussion
Ultimately, if the query is a row count, Spark will reading the Parquet metadata to determine the count. If the predicates are fully satisfied by the min/max values, that should work as well.
Attribution
I wanted to thank Cheng Lian and Nong Li for helping me to dive deeper in how this process works.
Leave a Reply