Skip to content
Denny Lee
Search
Spark
February 13, 2024
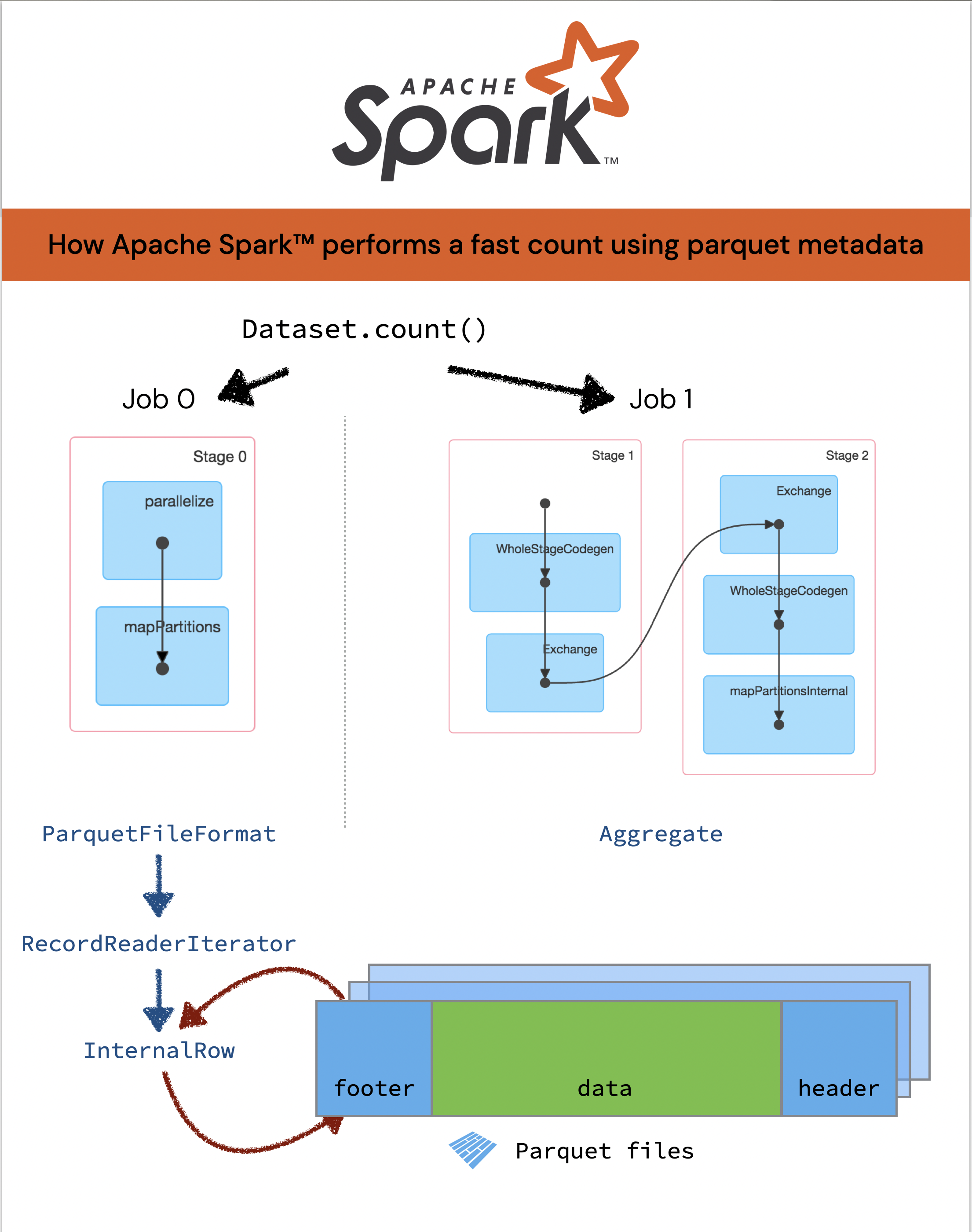
How Apache Spark™ performs a fast count using the parquet metadata
January 22, 2024
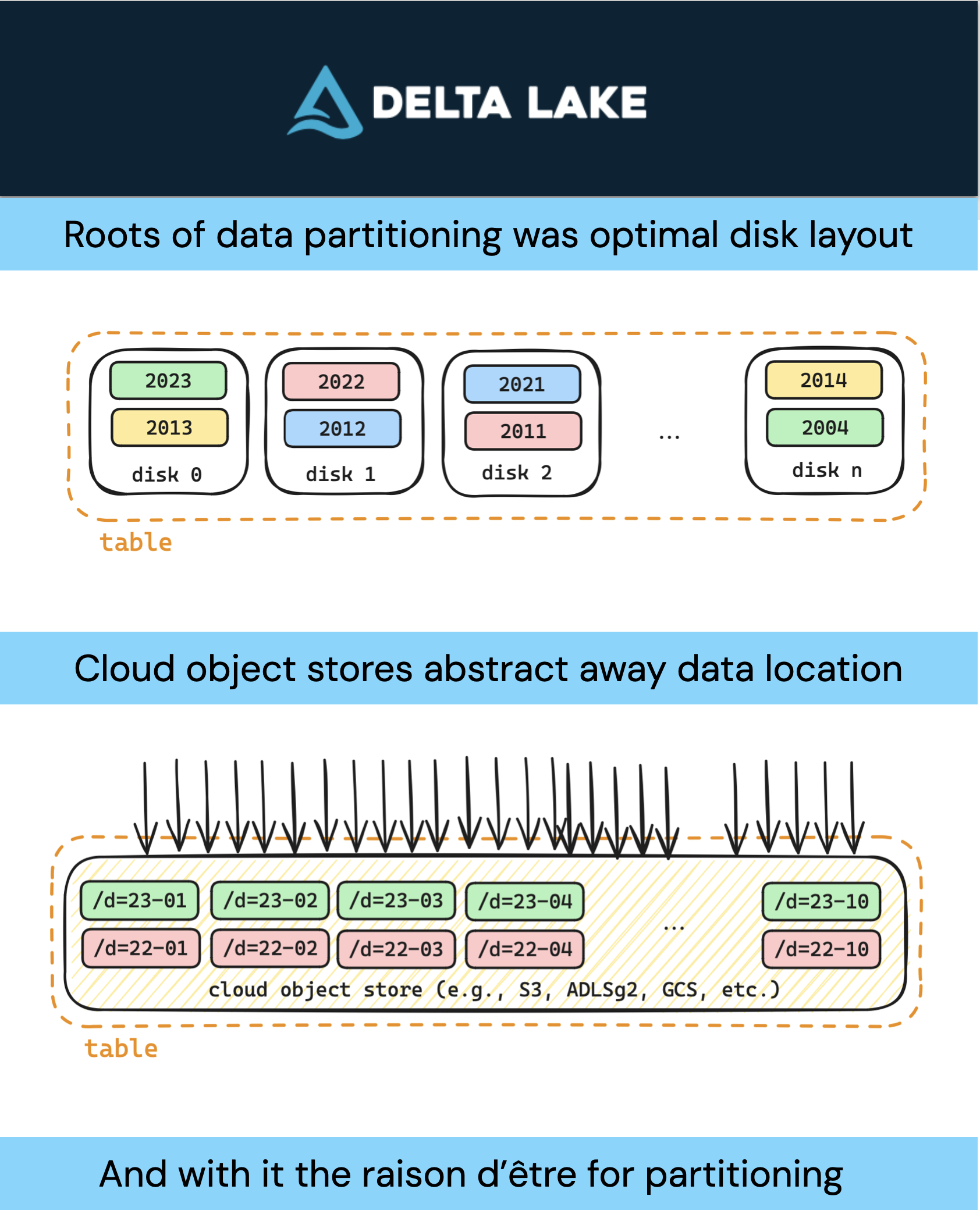
Organizing Data: Partition by Disk to Hive-style Partitioning
August 25, 2023
Why Structured Streaming and Delta Lake for Batch ETL?
March 20, 2023
Why does altering a Delta Lake table schema not show up in the Spark DataFrame?
May 28, 2016
On-Time Flight Performance with GraphFrames for Apache Spark
February 4, 2013
Installing Spark 0.6.1 Standalone on OSX Mountain Lion (10.8)
Loading Comments...
Write a Comment...
Email (Required)
Name (Required)
Website