The roots of Hive-style partitioning are disk-based partitioning of data for databases and data warehouses. The basic tenet was that many disks each returning a small amount of data was faster than a single disk returning a large amount of data. Basically, the physics of throughput (by how fast a disk was spinning) was directly correlated to query performance. But the introduction of cloud object stores (e.g., AWS S3) abstracted data from its physical location. While distributed query engines like Apache Spark™ can use Hive-style partitioning to improve query performance, it is not for the physical location of the data on cloud object stores.
Data Warehousing Data Partitioning
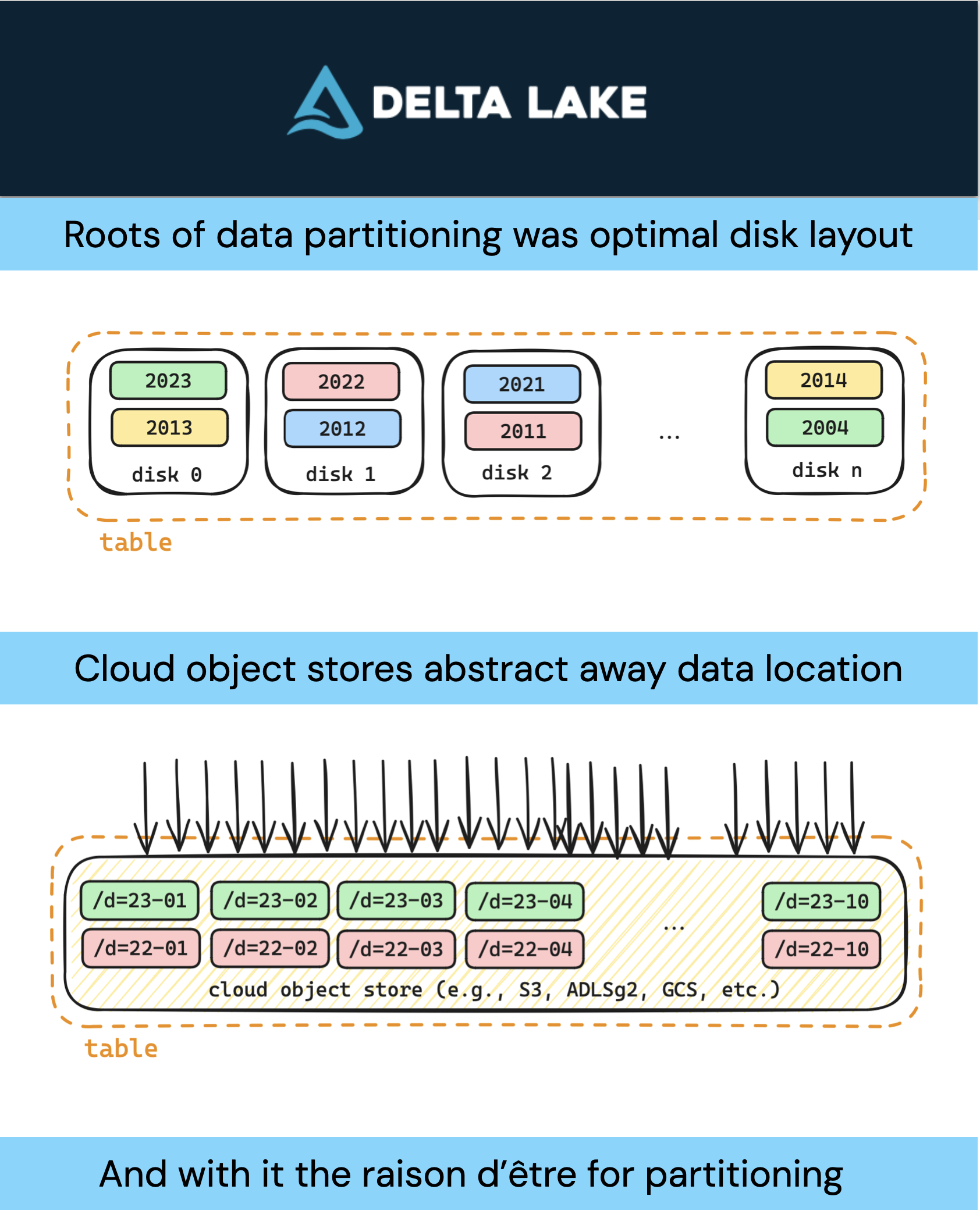
One of the earlier roots of data partitioning was for databases and data warehousing. At the time, these large data warehouses were built on top of proprietary databases comprised of many files. Speeding up performance requires distributing those files across multiple hard drives (disks or spinning media) of the computer/server.

For example, we can partition our data warehouse table by year and distribute the those files across multiple drives.

But in this configuration, when querying 2022 and 2023 data, you are only utilizing two drives. To improve performance, let’s try a different partitioning strategy.

For example, we can partition the table by year across all of the available drives. With more drives returning smaller amounts of data, we will increase the throughput thus improving query performance. But, things may slow down if you query 2022 and 2023 data at the same time.
With hard drives or spinning media, the rotational speed of the disk correlates directly to throughput. That is, faster disk = faster query. Two concurrent queries to the same disk slows down performance because the disk is randomly spinning (random IO) to provide the answer. It was often important to organize data and queries so the disk is spinning serially (serial IO), again for faster performance. Mike Anderson digs into this topic in his blog posts. Jimmy May and I dig into the topic of disk partition alignment as well.
Ultimately, this form of data warehousing data partitioning strategies is about how fast you can extract data from physical drives.
Hive-style Partitioning
As part of the era of Big Data, we created data lakes using Apache Hadoop and Apache Hive. We took many of the same data warehousing techniques and applied them to data lakes.

A Hive-style table partitioned by year and month has a file path such as /date=2023-01, /date=2023-02, ….
For Hive-style partitioning, instead of a single computer you are distributing the disks and data across multiple nodes (machines) in the Hadoop Distributed File System (HDFS). This was for both performance and durability to ensure there were copies of the data even if a machine failed. The path pointed to the location of the data.
Organizing Data on Cloud Object Stores
Cloud object stores (starting with AWS S3) abstract away the physical location of the data (e.g., drive). They provide “unlimited” scale but these are through web API calls. The physical location of the data within the same region has little-to-no impact on query performance.

In this case, data partitioning by disk no longer helps. From a disk storage in the cloud perspective, the query is unaware of the physical drives (spinning media or solid state drives).
API calls to access data on Cloud Object Stores
Instead of directory or file reads, queries ultimately make API calls to access the data on the cloud object store. The more concurrent API calls, the faster your query read and write performance.

Listing files on Cloud Object Stores is resource intensive
Even the listing of files in cloud object stores is resource intensive as it involves API calls.

Hive-style partitioning was not designed for Cloud Object Stores
Distributed query engines like Apache Spark™ leverage partitioning to improve query performance by slicing datasets smaller to fit into available memory and CPU. It is leveraging Hive-style partitioning to more quickly locate what data it needs to read and filter. Recall that Hive-style partitioning is an optimization for multiple drive layout utilizing disk read and writes. It is not designed for distributed concurrent API calls as it was designed before the latter existed..

Note, partitioning can still be useful to organize data, but not for file structure reasons. It helps a query engine find files faster thus reducing the amount of data it has to read when querying it. For example, Spark will need to only read data from /d=23-01 partition for January 2023 data.
Discussion
This post is a primer for the upcoming Optimize by Clustering not Partitioning Data with Delta Lake. It provides the raison d’être for Hive-style partitioning and provides the seed on how we may want to rethink how we organize our data when working with cloud object stores.
Leave a Reply